The VU Sound Corpus — Emiel van Miltenburg, Benjamin Timmermans and Lora Aroyo (2016)
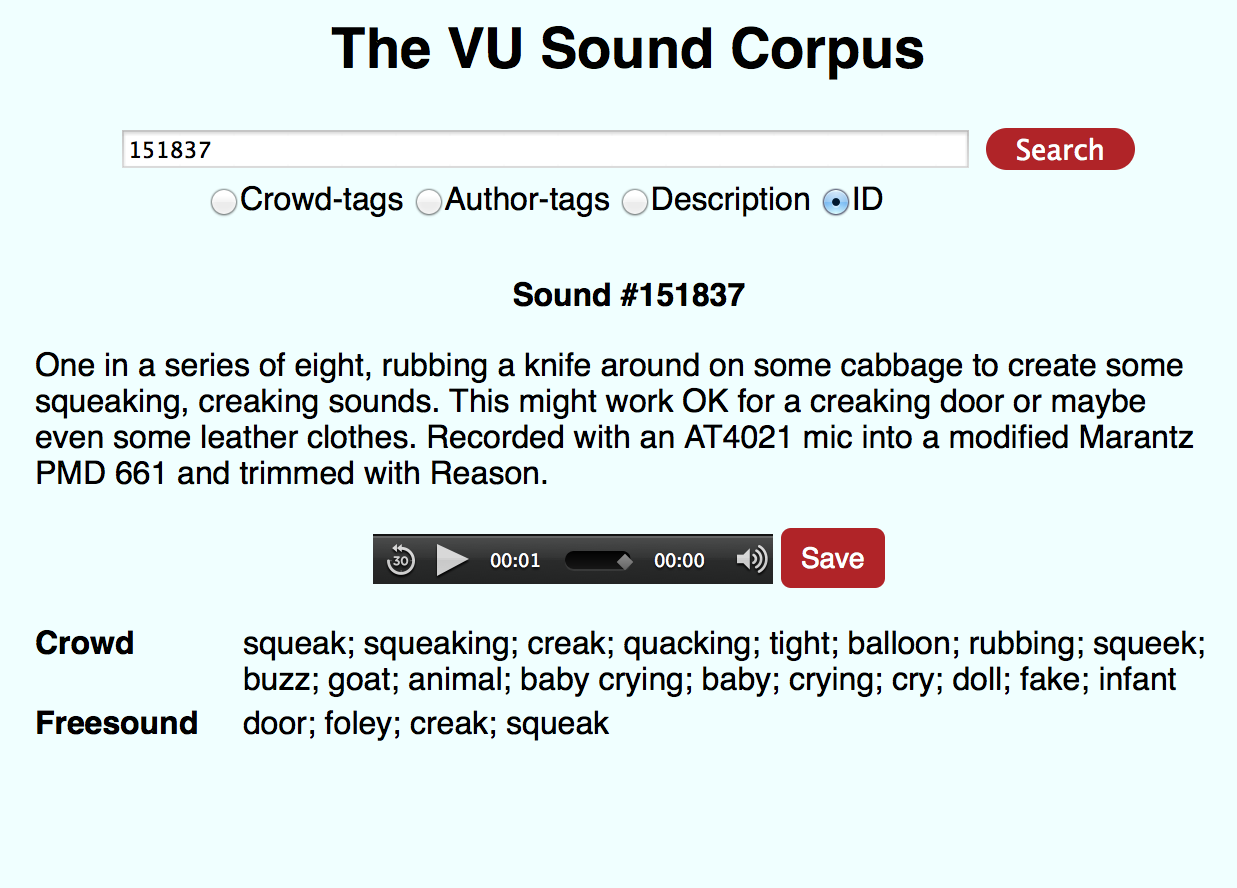 The VU Sound Corpus: Enter a keyword, for example ID: 151837 and learn how different participants label a sound: rubbing a knife on a cabbage sounds like a goat, and like a crying baby.
The VU Sound Corpus: Enter a keyword, for example ID: 151837 and learn how different participants label a sound: rubbing a knife on a cabbage sounds like a goat, and like a crying baby.
Adding more fine-grained annotations to the Freesound database. In: Proceedings of LREC 2016.
This paper presents a collection of annotations (tags or keywords) for a set of 2,133 environmental sounds taken from the Freesound database (www.freesound.org). The annotations are acquired through an open-ended crowd-labeling task, in which participants were asked to provide keywords for each of three sounds. The main goal of this study is to find out (i) whether it is feasible to collect keywords for a large collection of sounds through crowdsourcing, and (ii) how people talk about sounds, and what information they can infer from hearing a sound in isolation. Our main finding is that it is not only feasible to perform crowd-labeling for a large collection of sounds, it is also very useful to highlight different aspects of the sounds that authors may fail to mention. Our data is freely available, and can be used to ground semantic models, improve search in audio databases, and to study the language of sound.
Citation information
Annotations: Emiel van Miltenburg, Benjamin Timmermans and Lora Aroyo (2016).
The Freesound database: Frederic Font, Gerard Roma, and Xavier Serra (2013) Freesound technical demo. In: Proceedings of the 21st ACM international conference on Multimedia. ACM.