Understanding
of
language
by
machines
– an escape from the world of language –
Spinoza Prize projects (2014-2019)
Prof. dr. Piek Vossen
Understanding language by machines
1st VU-Spinoza workshop
Friday, October 17, 2014 from 12:30 PM to 6:00 PM (CEST)
Atrium, room D-146, VU Medical Faculty (1st floor, D-wing)
Van der Boechorststraat 7
1081 BT Amsterdam
Please RSVP via Eventbrite before October 03, 2014

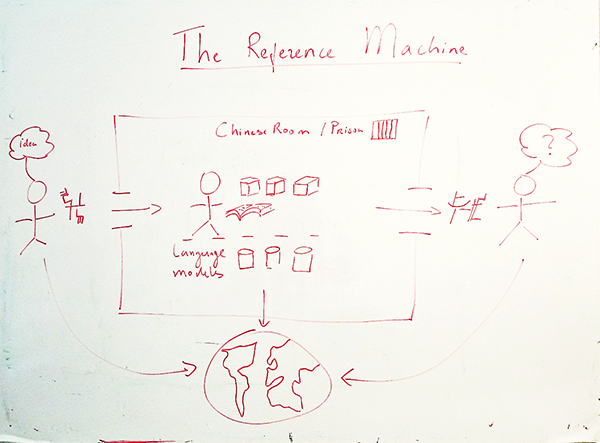
Can machines understand language? According to John Searle, this is fundamentally impossible. He used the Chinese Room thought-experiment to demonstrate that computers follow instructions to manipulate symbols without understanding of these symbols. William van Orman Quine even questioned the understanding of language by humans, since symbols are only grounded through approximation by cultural situational convention. Between these extreme points of views, we are nevertheless communicating every day as part of our social behavior (within Heidegger’s hermeneutic circle), while more and more computers and even robots take part in communication and social interactions.
The goal of the Spinoza project “Understanding of language by machines” (ULM) is to scratch the surface of this dilemma by developing computer models that can assign deeper meaning to language that approximates human understanding and to use these models to automatically read and understand text. We are building a Reference Machine: a machine that can map natural language to the extra- linguistic world as we perceive it and represent it in our brain.
This is the first in a series of workshops that we will organize in the Spinoza project to discuss and work on these issues. It marks the kick-off of 4 projects that started in 2014, each studying different aspects of understanding and modeling this through novel computer programs. Every 6-months, we will organize a workshop or event that will bring together different research lines to this central theme and on a shared data sets.
We investigate ambiguity, variation and vagueness of language; the relation between language, perception and the brain; the role of the world view of the writer of a text and the role of the world view and background knowledge of the reader of a text.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬ Program ▬▬▬▬▬▬▬▬▬▬▬▬▬▬
12:30 – 13:00 Welcome
13:00 – 13:30 Understanding language by machines: Piek Vossen
13:30 – 14:30 Borders of ambiguity: Marten Postma and Ruben Izquierdo
14:30 – 15:00 Word, concept, perception and brain: Emiel van Miltenburg and Alessandro Lopopolo
15:00 – 15:15 Coffee break
15:15 – 15:45 Stories and world views as a key to understanding: Tommaso Caselli and Roser Morante
15:45 – 16:15 A quantum model of text understanding: Minh Lê Ngọc and Filip Ilievski
16:15 – 17:00 Discussion on building a shared demonstrator: a reference machine
17:00 – 18:00 Drinks
For more information on the project see Understanding of Language by Machines.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬ RSVP ▬▬▬▬▬▬▬▬▬▬▬▬▬▬▬
Admission is free. Please RSVP via Eventbrite before October 03, 2014.
▬▬▬▬▬▬▬▬▬▬▬▬▬▬ Location ▬▬▬▬▬▬▬▬▬▬▬▬▬▬
Atrium, room D-146, VU Medical Faculty (1st floor, D-wing)
Van der Boechorststraat 7
1081 BT Amsterdam
The Netherlands
Parking info N.B. Campus parking is temporarily unavailable.